
User:Alvaro
works
[edit]- River
- Alène Lignon (Ardèche) Chère Ibie Mortagne (river) Ailette (river) Albarine Smagne Yon Lay (river) Abloux Auroue Diège Rhue (river) Céou Céor Brame Aubetin Asse (river) Othain Verzée Voueize Tardes (river) Semnon Salleron Briance Bouble Arz (river) Orbieu Barguelonnette Barguelonne Gijou Senouire Gesse Vère Guil Airain Vauvise Rupt de Mad Chée Chéran Indrois Clouère Auzoue Sorgues (river) Aujon Bléone Côle Ével Luzège Triouzoune Rère Chalaronne Vallière (river) Sevron Sâne Vive Sâne Morte Solnan Thoré Lizonne Fier (river) Colagne Chavanon Veyle Galaure Séoune Bourbre Lèze Petite Baïse Côney Chapeauroux Vaige Semme Barse Benaize Sormonne (river) Maronne Oudon (river) Lignon du Forez Blaise (Marne) Lignon du Velay Grosne (river) Madon Layon Boutonne Vègre Calavon Dadou Anglin Bouzanne Chassezac Dourdou de Camarès Arconce Meu Cérou Èvre Moder (river) Osse (river) Petite Creuse Bourbince Lunain Cosson Aveyron (Loing) Ouanne (river) Suippe Solin (river) Seugne Louge Touch (river) Ource
- Canal
- Canal du Loing ☭ Canal de Bourbourg ☭ Canal de Bergues ☭ Canal de l'Aisne à la Marne ☭ Canal des Ardennes ☭ Canal latéral à l'Aisne ☭ Canal latéral à la Marne ☭
- Related
- Aiguillon Rhue Hugues Cosnier Plateau de Lannemezan Aveyron (disambiguation) Moder
Useful :
- {{WikiProject France| importance=low | class=Start }} {{river}}
- {{iw-ref|fr|Alette|April 29, 2009|oldid=38280739}}
- Special:OldReviewedPages
- {{subst:uw-vandalism1|}} 1, 2, 3, 4
- {{subst:uw-test1|}} 1, 2, 3, 4
- WP:WARN
Alvaro
[edit]- commons:User:Alvaro/Ma galerie My gallery.
-

-

-

-

-

-
 War memorial in Dammarie-sur-Loing
War memorial in Dammarie-sur-Loing -








| fr | Cet utilisateur a pour langue maternelle le français. |
| en-2 | This user can contribute with an intermediate level of English. |
| de-1 | Dieser Benutzer hat grundlegende Deutschkenntnisse. |
| This user is a participant in WikiProject France. |
| This user is a participant in WikiProject Rivers. |
stats
[edit]- 14:52, 1 April 2009 (UTC) : 162,946
- 16:33, 6 April 2009 (UTC) : 161,230
- 18:14, 7 April 2009 (UTC) : 160,436
- 15:11, 15 April 2009 (UTC) : 157,493
- 12:20, 16 April 2009 (UTC) : 158,336
- 13:28, 25 April 2009 (UTC) : 157,401
- 16:25, 1 May 2009 (UTC) : 157,979
- 12:18, 5 May 2009 (UTC) : 157,258
- 20:35, 19 May 2009 (UTC) : 160,202
- 10:25, 5 June 2009 (UTC) : 158,605
- 14:19, 13 July 2009 (UTC) : 148,258
- 17:27, 24 August 2009 (UTC) : 146,307
- 14:40, 2 September 2009 (UTC) : 147,793
- 22:37, 18 September 2009 (UTC) : 150,234
- 16:13, 20 December 2009 (UTC) : 153,356
- 15:36, 5 March 2010 (UTC) : 163,136
- 06:50, 19 April 2010 (UTC) : 153,727
- 10:06, 19 August 2010 (UTC) : 135,534
- 19:17, 13 September 2010 (UTC) : 132,532
- 09:25, 20 September 2010 (UTC) : 133,133
- 23:03, 26 October 2010 (UTC) : 135,528
- 18:49, 30 October 2012 (UTC) : 133,153
- 04:52, 26 July 2013 (UTC) : 121,689
- 14:07, 18 February 2014 (UTC) : 130,769
- 22:52, 15 August 2015 (UTC) : 118,983
Current {{NUMBEROFACTIVEUSERS}} : 117,562
tools
[edit]- Pour Vienne : {{otheruses4|the French department|the French city|Vienne, Isère}}
- Pour Vienne : {{distinguish|Vienna}}
- Sur Asse : {{for|a tributary of the [[Durance]]|Asse River}}
people
[edit]Through my watchlist, I often meet Ksnow (talk · contribs), Markussep (talk · contribs), Dickeybird (talk · contribs)...
signpost
[edit]
Courts order Wikipedia to give up names of editors, legal strain anticipated from "online safety laws"
Indian courts order Wikipedia to take down name of crime victim, editors strive towards consensus
Courts order Wikipedia to give up names of editors, legal strain anticipated from "online safety laws"
Indian high court demands names be given up
[edit]As reported here in July, India's Asian News International (ANI) has brought Wikimedia Foundation to court. The allegation is of publishing defamatory content about ANI, at the English Wikipedia article which stated at that time that they had "been accused of having served as a propaganda tool for the incumbent central government, distributing materials from a vast network of fake news websites, and misreporting events on multiple occasions". The Foundation is now being compelled by the Indian court to reveal personal information of some editors who have edited the article, according to Livemint (report) and The Hindu (report). The next hearing will be on 25 October 2024. Wikipedia's internal consensus of ANI's suitability as a citable source for articles (as in this 2021 discussion and WP:RSPANI) generally holds it to be somewhere between marginally reliable and generally unreliable for general reporting, prudent to give in-text attribution for potentially contentious claims, and generally unreliable in its coverage of domestic and international politics (and other topics that the government of India has a stake in). – rs
"Very demanding" new "online safety" laws start to put legal strain on Wikipedia
[edit]In European courts, on the other had, things have been going better for the Wikimedia Foundation lately. In the UK, British-born Swiss lawyer Matthew Parish sued the WMF for libel, because the article about him (correctly) noted his legal issues; however, the case has been dismissed by High Court judge Karen Steyn.
And as highlighted by Techdirt ("The Wikimedia Foundation Successfully Sees Off Another SLAPP Suit, But More Protection Is Needed Globally"), WMF recently reported another legal victory in Germany ("Wikimedia Foundation defeats gambling magnate’s lawsuit in Germany"). The Foundation characterized it as having "had all the hallmarks of an illegitimate “SLAPP” lawsuit: a strategic lawsuit against public participation. SLAPPs are lawsuits designed to force organizations and individuals to remain silent on legitimate matters of public interest. [...] The [German] Wikipedia article in question names Mladen Pavlovic as one of three co-founders of Tipico, a major European gambling company headquartered in Malta." According to WMF, this was well-sourced public information. Yet "Pavlovic engaged a reputable German law firm to threaten the Foundation with legal action unless we agreed to censor the Wikipedia article. After consulting members of the German Wikipedia community, we refused the lawyers’ demand." Pavlovic then filed a lawsuit which "was especially intensive for our team because of the unusual number of legal briefs to which we were asked to reply. [...] These usually repeated earlier arguments, and introduced—in our opinion—increasingly thin or irrelevant new ones." As summarized by Techdirt "That approach seems a conscious attempt to deplete Wikimedia’s limited financial resources [for legal defense], increasingly under strain" from what the WMF blog post describes as a changing legal environment:
The Foundation’s legal team now also has to deal with a wave of new and very demanding “online safety” laws across the world: for example, the EU Digital Services Act (DSA) and the UK Online Safety Act. These conditions force us to be as efficient, creative, and effective as possible, including in lawsuits like this one.
These laws may not have directly affected Pavlovic's lawsuit yet, as it predates the DSA. However, according to WMF, it fits a resource-draining pattern: "The Foundation faces several SLAPP-like cases each year" (citing examples including the still unresolved Caesar DePaço lawsuit in Portugal, see previous Signpost coverage). The Foundation's post ends with a call for anti-SLAPP reform (about which, according to Techdirt, "Some progress has already been made" in the EU and UK). However, it reiterates that insufficient anti-SLAPP protection is only part of the legal challenges affecting Wikimedia projects, briefly noting other concerning developments:
Privacy-infringing laws like France’s data retention law, and emerging online identity requirements, together with laws that give government authorities insufficiently regulated powers to order content takedowns, are also a significant issue.
– H
Gen Z can save Wikipedia from its "existential crisis", Stephen Harrison says
[edit]
Wikipedia beat reporter Stephen Harrison, who is best known for his articles in Slate, has recently been busy promoting his debut novel, The Editors, focused on a fictionalized version of the platform (named "Infopendium") that is suddenly caught up in global cyberwarfare during the COVID-19 pandemic — see previous coverage from the Signpost here and here.
Now, though, he has written an article for The Guardian detailing his view on the future of Wikipedia, which is subtitled "The world's most important knowledge platform needs young editors to rescue it from chatbots – and its own tired practices". Harrison says Wikipedia is currently facing an "existential crisis" due to the emergence of AI applications and large language models, which could potentially undermine the platform's visibility. According to Harrison himself, Gen Z editors are the best-equipped to help Wikipedia survive and, possibly, even thrive in this new context: he pointed out a 2022 survey reporting that about 20% of Wikipedia editors were between the ages of 18 and 24, while also noting the role of young contributors in recent debates on the incorporation of chatbot-generated content on the encyclopedia. The article notably includes a short interview with a very prominent Gen Z editor: the latest Wikimedian of the Year, Hannah Clover.
As for those "tired old practices", Harrison has his say about the sometimes inflexible norms and normalizing institutions of Wikipedia, not to mention mobile-unfriendly editing interface, which he calls "issues that dissuade the younger generation from joining the cause". For instance, he says that the tasks taken on by new editors from a decade ago – ones letting them dip their toes in the editing experience in a low-risk, low-consequence environment – are now more highly automated, leaving a lack of "clear entry points". This in turn may lead today's new editors to unknowingly get into contentious topics where they experience off-putting "harsh feedback" from the more established editors. Harrison left unsaid that there are more contentious topics and areas under sanctions than ever before (see prior Signpost coverage that noted "policies of closure and the formalization of boundaries, rules and routines").
Whether the new generation can adapt to, or reform the tired Wiki, and eventually make it their own as they become the normies, or whether they abandon it for something new, only time can tell. – O, B
How do you give away 25 million euros?
[edit]Joshua Yaffa in The New Yorker explains (paywalled) the difficulties Marlene Engelhorn had in giving away 25 million euros through the Guter Rat für Rückverteilung (Good Council for Redistribution). Engelhorn had inherited her money from a fortune that started with the founding of BASF and later grew with the Boehringer Mannheim pharmaceutical company. She felt that she should give away most of it to reduce wealth inequality in Austria and as a learning experience to guide others who have the same goal. Engelhorn was keeping about 10% of her money and about €3 million was spent on implementing a process where a citizen council – a group of 50 ordinary Austrians selected by lottery – decided where the money should go. This included the use of moderators who "wield huge power" according to an academic who studies this area. They have "an emphasis on getting things done ... it can all mean that, in the moment, you take away the possibility for improvisation or dissent.”
Nearly eighty organizations were selected by the council, with an average of €312,500 for each organization. "Wikipedia" (as they called the Wikimedia Foundation) turned out to be the most controversial choice:
The idea came from a Vienna resident in his mid-thirties [...]. He saw Wikipedia as addressing many of the council’s core values: democracy, accessibility, transparency. The idea was immediately opposed by Kyrillos, a high-school student and the council’s youngest member. “We have a lot of other, more important issues to address here,” he said. Anyway, he went on, his teachers wouldn’t allow him to use Wikipedia as a source in his papers—why give it money?
Factions emerged. Some saw Wikipedia, a nonprofit based in the U.S., as an inefficient use of the council’s resources. Others viewed the effort to nix it as a violation of the council’s ground rules. [...]
The Wikipedia debate was ultimately settled with a compromise. The members of the education group agreed to give the organization fifty thousand euros, a small portion of their total.
Thanks Marlene!
The name "Engelhorn" may ring a bell for longtime Signpost readers. In 2015, the Reiss Engelhorn Museum in Mannheim, Germany filed lawsuits against the Wikimedia Foundation, Wikimedia Deutschland and a Wikimedia Commons user over the use of photographs of public domain artworks on Wikimedia projects. (Cf. Signpost coverage: "Wikimedia Foundation, Wikimedia Deutschland urge Reiss Engelhorn Museum to reconsider suit over public domain works of art", "Wikimedia lawsuits in France and Germany". While the museum prevailed in court against the Foundation, the EU Copyright Directive subsequently made such assertions of copyright over faithful reproductions of public domain works impossible.) Indeed the museum is so named after one of its sponsors, German industry titan Curt Engelhorn (1926–2016), a relative of Marlene Engelhorn. As detailed in the German Wikipedia article about him, back in 1997, in what was Europe's largest company takeover to date, he had controversially managed to sell off the family's company holdings for 19 billion DM without paying any taxes to the German state, and Marlene Engelhorn has publicly criticized his (lack of) philanthropy.
In brief
[edit]_2.jpg)
- "Can You Trust Dr. Wikipedia?": The Office for Science and Society of McGill University has recently discussed the accuracy of Wikipedia's medical content and how difficult it is to address some questions. What's your purpose in studying "accuracy"? Which language version are you interested in? When was your sample of articles taken? Despite a horrifying lede invoking toasters (see previous Signpost coverage) and John Seigenthaler, the authors conclude that it is "useful and fast" for many purposes, including for medical students approaching their licensing exams. They also praise WikiProject Medicine and the use of classes that teach health science students to edit Wikipedia.
- New problems emerge in Iran: Pejman Amiri reports in NewsBlaze about the Iranian government's attempts to manipulate and censor the Farsi Wikipedia, while openly accusing the head of the Iranian Wikimedians User Group, Mohammad Heydarzadeh (known on-Wiki as Darafsh), of "trying to gain higher and sensitive access to the Wikimedia Foundation", among other things. While much of this report is very difficult for The Signpost to verify, you can see previous Signpost coverage of a global ban possibly linked to actions of the regime.
- Do it, or else: According to a recent report from OC Media, Farid Pardashunas, an Azerbaijani blogger who had received a presidential award in 2021, revealed the identities of contributors to the Azerbaijani Wikipedia – including admin Solavirum – who had deleted about 3,000 articles on soldiers killed in the Second Nagorno-Karabakh War; in what essentially represents blackmail, the blogger urged the contributors to restore the pages, while threatening to send their personal data to the national State Security Service.

- Bias in Judaism and Zionism related articles: Many newspapers have looked at potential bias and reliability issues in articles relating to Judaism and or Zionism:The latter source mentions there was an attempt at the reliable sources noticeboard to downgrade The Jewish Chronicle back in May. However, it should be noted that the aforementioned newspaper is just now in the middle of a notable scandal involving fabricated news stories and opaque ownership, with Israeli sources first sounding the alarm. See also the ongoing discussion over at the Noticeboard.
- "Wikipedia defines Zionism as 'colonialism', sparking outrage" (Israel Hayom)
- "War over Wikipedia's Definition of Zionism Pits Provoked Users Against Biased Editors" (The Jewish Press)
- "Wikipedia blasted for 'wildly inaccurate' change to entry on Zionism: 'Downright antisemitic'" (Washington Examiner)
- "From Bias to Balance: Jewish Editors on Wikipedia" (Times of Israel blogs)
- "Wikipedia has an antisemitism problem" – opinion, (The Jerusalem Post)
- "Wikipedia's anti-Israel bias is a feature, not a bug" – (The Jewish Journal of Greater Los Angeles)
- Paid editing saga involving Portland commissioner Rene Gonzales continues: Several regional media sources, including The Oregonian and KOIN, reported that Portland city commissioner and candidate for mayor Rene Gonzalez has been cleared of wrongdoing by the City Auditor's Office on September 16, as evidence about Gonzalez's use of local funds for paid editing on Wikipedia was deemed as insufficient to prove a violation of the city's campaign finance law. See previous Signpost coverage on the matter here and here.
- Do Wikipedia – responsibly: Whilst being best known as an actor and the firstborn son of Brad Hall and Julia Louis-Dreyfus, Henry Hall is also a musician. Back in August, he released his second studio album, Stop Doing Funny Stuff, which contains the single "Wikipedia-ing Poison Snakes", a solemn-sounding testimony from a terminally online man who keeps going down rabbit holes on Wikipedia, ranging from predictive text to Booksmart, in order to distract himself from "his own head, his own bed, every word he's ever [freaking] said". If you feel like this song is too relatable, just know we're in this together (and many of us need some help).
Indian courts order Wikipedia to take down name of crime victim, editors strive towards consensus
Indian high court demands name be taken down
[edit]

In the wake of a high-profile sexual assault in Kolkata last month, India's courts have demanded that Wikipedia remove of the name of a victim from an article on the crime. While some national and local media outlets reported the name of the victim at the time, as did various international media sources, the laws of India, prohibit media from publicizing the names of victims of especially heinous crimes.
The incident was widely reported on 10 August, the day after it occurred; English Wikipedia editors created the article a day after that. By 13 August, editors began debating whether to mention the victim's name. On 16 August, that debate became part of a discussion on how to title the article, which was ongoing until 9 September, when the disagreement about including the name split into its own discussion. All of this was part of the consensus-building process usual and familiar to editors, where editorial decisions are reached by group discussion about how to implement policies and guidelines.
On 16 September, the Supreme Court of India ordered Wikipedia to remove the name. The Free Press Journal (report), The Hindu (report), and The Times of India (report) are among the many sources to report on the court's order. In this case, and as often happens when institutions make requests of Wikipedia, the court made its request with some presumption that Wikipedia has an editorial leader who can issue binding orders. As is known among Wikipedia editors, there is no such person: even the Wikimedia Foundation does not control the content of articles under Wikipedia's policies.
Wikipedia editor deliberation
[edit]In response to the court decision, the legal department of the Wikimedia Foundation posted a notice on the talk page of the article, encouraging Wikipedia editors to deliberate carefully on the issue and "explain clearly why you feel the balance of interests lies one way or the other, in order to reach consensus accordingly". Wikipedia editors did that, and reached a decision to exclude the victim's name. User:Tamzin, a volunteer editor, closed the discussion and authored the consensus statement.
The final decision was to exclude the name from the article. While closing statements typically are descriptions written by Wikipedia editors and for Wikipedia editors, Tamzin included a summary explanation of the overall process in anticipation that the court, media, and public observers may wish to examine both the consensus and discussion. It will not come as a surprise to Wikipedia editors that Wikipedians value their editorial independence. The closing statement emphasizes that Wikipedia editors did not arrive at that decision at the behest of the court, but rather because community deliberation found reasons for doing so and because a supermajority of editors supported the decision.
Arguments for and against name inclusion
[edit]The article is 2024 Kolkata rape and murder incident, and it begins, "On 9 August 2024, a 31-year-old female postgraduate trainee doctor at R. G. Kar Medical College and Hospital in Kolkata, West Bengal, India, was raped and murdered in a college building."
One set of arguments about the name relates to victim's rights and women's rights. The argument in favor of naming the victim is that her story becomes known and enables activism to reduce violence against women. The argument opposed is that in some cases, and this case in particular, naming the victim greatly endangers and disturbs their family, social network, colleagues, and supporters.
Another set of arguments relates to censorship of Wikipedia and Wikipedia's own WP:NOTCENSORED policy. The argument in favor of publishing the name is that maximal freedom in publishing is the preferred position. The argument opposed is that naming the victim is not a censorship issue, as Wikipedia will definitely have an article on the crime, and that article does not benefit significantly by including the name of the victim.
Another set of arguments is about following the lead of what other media outlets do. Arguments in favor of publishing the name point to seeming WP:Reliable sources and reputable journalists who are publishing the name. Arguments opposed to publishing the name make various claims, including that sources publishing the name are mistaken, or that they have since removed the name, or that the higher quality sources do not publish the name while lower quality sources do. Wikipedia editor User:Fowler&fowler checked various sources and reported which ones do not publish the name.
A final set of arguments is on the practicality of collaboration between Wikipedia and the government of India. The argument in favor of publishing the name assumes that other arguments establish that Wikipedia editors should publish the name, and in that context, it is best for Wikipedia as an international media source outside the jurisdiction of Indian government control to disregard the government request. Arguments opposed to publishing the name include respect for the expertise of those courts, respect for national decision making to know what is best for local culture, anticipation of a good future of peaceful collaboration with the government of India by granting this request, and concern for the burden on Wikipedia editors in India if they bear the responsibility of an online global decision including non-Indian Wikipedia editors.
– BR
A Wikipedian at the 2024 Paralympics
In 2011, the Australian Paralympic Committee (now Paralympics Australia) commenced a project to document its history. This included collecting documents and museum pieces and conducting oral history interviews with Paralympians. An online component was recognised as being important, and Wikipedia was identified as part of that. Since then, Paralympics Australia and Wikimedia Australia have collaborated to produce thousands of articles that keep receiving millions of page-views each year. As part of the project, I attended the Paralympic Games in London in 2012, in Rio de Janeiro in 2016, and now in Paris in 2024 as a media representative, with accreditation supplied by the Paralympics Australia. This time, I took a photographer, GailLeenstra, with me.
-
 Equestrian – France's Alexia Pittier
Equestrian – France's Alexia Pittier -
 The most iconic of the Paralympic venues, the Equestrian on the grounds of the Chateau de Versailles
The most iconic of the Paralympic venues, the Equestrian on the grounds of the Chateau de Versailles


Media accreditation meant that I had access to the media tribunes at the venues and could attend any game, even when the event was sold out (as was usually the case). It meant that I could visit the Paralympic Village and interview athletes after the game in what is called the Mixed Zone. It meant that we could use the buses of the TC, the Olympic transport system. It meant we had access to the resources of the Main Press Centre (MPC) and the Venue Media Centres (VMCs), which provided wired and wireless internet access, desks to work at, staff to help us, and lockers to store our equipment. It meant that my photographer had access to prime photographic positions not accessible by the public. It also meant that she had access to the Nikon store at the Stade de France, where she was able to get some of her equipment repaired and borrow some very expensive equipment for the duration of the games to supplement the gear she had brought with her from Australia – all for free.
-
 Opening ceremony – as seen from the media tribune
Opening ceremony – as seen from the media tribune -
 Opening ceremony – dancing Phryges
Opening ceremony – dancing Phryges


The image of Wikipedia has undergone a dramatic transformation in that time I have been working on the Australian Paralympic Project. In London in 2012, there was a tendency of the mainstream media to regard us as not being "real journalists". There was none of that in Paris, quite the opposite in fact; mainstream media representatives repeatedly told us how much they appreciated our efforts, how they used Wikipedia as reference all the time, and how impressed they were with its accuracy.
-
 Wheelchair basketball – Team USA – From left to right: Rose Hollermann, Courtney Ryan, Rebecca Murray, Natalie Schneider and Lindsey Zurbrugg
Wheelchair basketball – Team USA – From left to right: Rose Hollermann, Courtney Ryan, Rebecca Murray, Natalie Schneider and Lindsey Zurbrugg -
 Swimming – Australia's Timothy Hodge
Swimming – Australia's Timothy Hodge


Support from the Paralympics Australia did not end in Australia. In Paris, they had set up headquarters at a site near the Paralympic Village known as "Our Mob", which contained meeting rooms, a TV studio, dining room and a McCafé concession (McDonald's being one of their sponsors). Tim Mannion, the General Manager of Communications, gave generous and welcome assistance and support to our efforts, including providing passes to the opening and closing ceremonies. Unlike the Olympic opening ceremony, the Paralympic opening ceremony was held in beautiful weather. Some 65,000 spectators packed into the Place de la Concorde for the first ever Paralympic opening ceremony to be held outside a stadium. GailLeenstra was chosen as one of select group of photographers chosen to accompany the lighting of the Paralympic cauldron.
-

-
 Paracanoeing – From further to closer: Hungary's Dalma Boldizsar, Thailand's Wasana Khuthawisap, Australia's Susan Seipel and Great Britain's Charlotte Henshaw
Paracanoeing – From further to closer: Hungary's Dalma Boldizsar, Thailand's Wasana Khuthawisap, Australia's Susan Seipel and Great Britain's Charlotte Henshaw


In Sydney, London and Rio, multiple venues were concentrated in a multi-sport precinct, but in Paris, the venues were widely scattered around the city. This is a model considered by many cities planning to hold the Olympics and Paralympics, because it allows the city to make use of existing facilities, saving the substantial cost of building new ones. It is not cheap, however! It came at a substantial cost in increased security, transportation and manpower through duplication. Venues required considerable upgrades, refurbishment and fitting out for the games. Three new venues had to be built, and Paris Metro lines were extended. Not to mention the 1.6 billion euros spent on cleaning up the Seine and Marne to make them fit to swim in. The police presence was overwhelming, with about 45,000 police and 10,000 troops on hand. All were heavily armed, with automatic weapons in case Hamas decided to put in an appearance. Roads near the venues were closed to vehicle traffic.
-
 Wheelchair rugby – Australia's Chris Bond against Great Britain
Wheelchair rugby – Australia's Chris Bond against Great Britain -
 Wheelchair rugby – Australia's Chris Bond against France
Wheelchair rugby – Australia's Chris Bond against France


Getting from one venue to another involved a trip on the Paris Metro using the Navigo cards issued to us as part of our media kit. Each day we criss-crossed the city on the Metro as we moved from one venue to the next. Fortunately, the Metro was super-efficient, with trains leaving every couple of minutes. Getting to venues in the metropolitan area took about a half an hour. (The locals told us that the Metro had never been so efficient nor, with the enhanced police presence, had they ever felt safer.) This meant that each day started with critical decisions about what events we would cover that day. Priority was given to events with Australian participation (especially medal chances), since our media accreditation was so generously provided by Paralympics Australia, but the athletes of other countries (especially the English-speaking ones) were by no means neglected. A mobile phone app told us what trains and buses to take to get from one place to another. It knew the location of the venues, train stations and bus stops, the bus and train schedules, and how crowded they were, encouraging you to take less crowded services.
-
 Wheelchair basketball – the Netherlands' Cher Korver, Saskia Pronk and Ylonne Post, and Canada's Arinn Young and Rosalie Lalonde
Wheelchair basketball – the Netherlands' Cher Korver, Saskia Pronk and Ylonne Post, and Canada's Arinn Young and Rosalie Lalonde -
 Wheelchair basketball – Canada's Kady Dandeneau, Rosalie Lalonde and Puisand Lai and Great Britain's Jade Atkin, Robyn Love and Laurie Williams
Wheelchair basketball – Canada's Kady Dandeneau, Rosalie Lalonde and Puisand Lai and Great Britain's Jade Atkin, Robyn Love and Laurie Williams


As it turned out, there were some other foreign Wikipedians present, but they lacked our accreditation and (quite understandably) had different priorities. This meant that Wikipedia had broad coverage and having Australian Wikipedians on site was fully justified by the coverage. We tried to see as many sports as possible: our coverage included Boccia, Cycling, Equestrian, Paracanoe, Triathlon, Wheelchair Basketball and Wheelchair Rugby. Cycling and Equestrian events were located well out of town, requiring a day trip on the Metro, Réseau Express Régional, and the TC.
-
 Paralympics Australia President Alison Creagh (left) and Australian Chef de Mission Kate McLoughlin (centre) present Hawkeye7 with a scarf
Paralympics Australia President Alison Creagh (left) and Australian Chef de Mission Kate McLoughlin (centre) present Hawkeye7 with a scarf -



Between 23 August and 9 September, articles created by the History of the Paralympic movement in Australia project garnered a total amount of 2,226,684 page views, while more than 1,200 images were uploaded. These pages and pictures will be a lasting legacy, to be enjoyed by readers for years to come.
asilvering's RfA debriefing
- asilvering's request for adminship was closed as successful on September 6, 2024.
First, the bullet points:
- It turns out a week is a really, really long time;
- Even if your RfA isn't contentious or stressful, it will probably be exhausting;
- Good nominators might not be essential, but I can't imagine having done RfA without mine; a steady hand on the tiller really, really helps (thanks especially to Vanamonde93);
- Designated monitors are a blessing (thanks theleekycauldron), especially when you're doing the discussion-first format and you would like some acknowledgement that you didn't somehow transclude your RfA straight into the void;
- If I may offer advice to future RfA hopefuls: don't post answers to questions right away. Write the answers in a text file, go take a nap, and then post them.
- If I may offer advice to future RfA participants: if you could not, without being overcome by embarrassment, apply your question/vote to both a) a teenager of your acquaintance and b) your grandmother, you should probably rephrase it.
As for how I got here: Vanamonde93 asked me if I was interested in running some time ago, but I deferred for a number of reasons that became more obviously hollow as time went on. For one, "I'm too busy" doesn't work as a very good excuse if you just go find something else to do, like starting a new kind of GAN backlog drive. My second nominator was an easy choice, but that doesn't mean I wasn't nervous about asking. (Don't laugh, czar!) Reading the nomination statements made my heart grow three sizes and also made me want to disappear into the wallpaper. (I'm not good at praise.)
For a little while, I was of a mind to wait out the end of the discussion-period trial, but once I'd got my nominators lined up, it started to feel like I just needed to get it over with. Then, right after I'd said, "alright, now's good, let's do this," Femke showed up in my inbox asking if I'd ever thought of running. It felt so good to be able to tell someone, "you're just in time!" instead of brushing them off with some kind of excuse.
I tried my level best to ignore all the discussion and voting while it was happening, but it turns out that's really hard – not just because it takes willpower, but also because MediaWiki kept showing me the discussion section whenever I tried to preview my answers to the questions. And it's very hard to avoid knowing the precise count once voting starts, since that's right at the top of the page. So I gave up, and read everything. If you're thinking of RfA and you're the anxious sort who will be constantly fighting the temptation to check in, line up something to do with friends/family so you don't glue yourself to the refresh button. There's no way around this bit. It sucks, and a week is a long time.
Luckily for me, people had really nice things to say. I really appreciate everyone who participated and everyone who came by to congratulate me afterwards. I'm doing my best to avoid the mushroom effect and to remain indifferent to both praise and blame. Thank you all for ignoring and then quietly removing the joke oppose; I was a bit worried they'd be murdered. As for the discussion period, I do think it helped things remain civil and on-track, but I'm ambivalent on the experiment overall.
Being an admin has been fun so far. Everyone's been really helpful, and if I've been driving anyone crazy with all my questions, they've been kind enough not to tell me. Special thanks to Aoidh, who has already stopped me from doing something stupid, kindly and firmly, like disarming a wayward toddler running with scissors.
Maybe my opinion isn't worth much, since I had such a smooth RfA compared to so many others, but if you think you'd probably succeed at RfA and you're holding back since it sounds like a bad way to spend a week: I think you should go for it.
It's possible that someone will drag up something stupid you said four years ago and try to rub your nose in it, or that some personal flaw of yours will be magnified beyond all reason. It's possible some people will try to use your RfA as a soapbox to complain about policies or norms they dislike. It's very likely that you will spend the whole week waiting for the other shoe to drop, whether any of those things happen or not. Even an uncontentious RfA can be an exhausting and unpleasant experience – mine was all of those things.
But it's also very likely that, over the course of a week, somewhere between one and three hundred people will show up to say something nice about you. Many of those people will be folks whose opinion you really, truly value. Some of them will be people you can't remember ever hearing of before, but who nonetheless have something deeply gratifying to say. You should run.
Plus, now I can tell my colleagues that I "have tenure, on Wikipedia." I'm sure they'll all be very impressed.
Are you ready for admin elections?

Encouraging news from the RfA review, including admin elections being set to start trials in October
[edit]
Will the new RfA reform come to the rescue of administrators?
16 May 2024
Jimbo's NFT, new arbs, fixing RfA, and financial statements
28 December 2021
Editors discuss Wikipedia's vetting process for administrators
26 September 2021
Administrator cadre continues to contract
31 July 2019
The Collective Consciousness of Admin Userpages
31 January 2019
The last leg of the Admin Ship's current cruise
31 July 2018
What do admins actually do?
29 June 2018
Has the wind gone out of the AdminShip's sails?
24 May 2018
Recent retirements typify problem of admin attrition
18 February 2015
Another admin reform attempt flops
15 April 2013
Requests for adminship reform moves forward
21 January 2013
Adminship from the German perspective
22 October 2012
AdminCom: A proposal for changing the way we select admins
15 October 2012
Is the requests for adminship process 'broken'?
18 June 2012
RFAs and active admins—concerns expressed over the continuing drought
14 February 2011
RfA drought worsens in 2010—wikigeneration gulf emerging
9 August 2010
Experimental request for adminship ends in failure
13 October 2008
Efforts to reform Requests for Adminship spark animated discussion
23 April 2007
News and notes: Arbitrators granted CheckUser rights, milestones
6 February 2006
Featured picture process tweaked, changes to adminship debated
27 June 2005
- Soni, the author of this story, was active in drafting the current reform proposals for the Requests for adminship process.
As part of WP:RFA2024, multiple RfA reform attempts have completed trials or are currently under review: you can read previous coverage on the matter by The Signpost in the 16 May issue.
There has already been consensus to add a reminder of RfA civility norms to WP:RFA, as well as limit suffrage to only extended-confirmed voters and formally require all nominees to also be extended-confirmed. All of these proposals were implemented in the last few months.
The "discussion-only period" trial has come to an end this month, having converted five different RfAs (non SNOW-closed) to have "discussion only" for the first two days out of the seven-day period. After this initial trial, Phase II discussions are ongoing to determine if this proposal will become permanent.
As per the outcome of the related Phase II discussion, admins can now designate themselves as monitors for RfAs, subject to minimum expectations for their conduct during the whole process. The full list can be found at WP:MONITOR. This proposal is intended to improve enforcement of civility guidelines during RfAs.
Phase II for the administrator recall proposal has also recently finished, having waited for a closer for several months. It will allow a community-initiated path to de-adminship by requiring certain admins to submit and pass their RfA again. Further discussion is ongoing on the next steps for this process.
Finally, the Admin Elections procedure is expected to trial in October: it will be a one-time trial to allow an alternate path to adminship, parallel to RfA. Candidates can sign up from 8–14 October, before entering a discussion period from 22–24 October, which will then be followed by a SecurePoll private voting session from 25–31 October. —S
U4C elections end with just one new member seated
[edit]The special elections for the Universal Code of Conduct Coordinating Committee (U4C) concluded earlier this month, with the election of just one candidate. With 613 votes cast between the 18 eligible candidates, only Ajraddatz (for the North America seat) achieved the 60% support-to-support+oppose ratio required. This gives the U4C just enough members (8 out of 16 seats) to establish their quorum, though it remains to be seen how U4C will handle inactive members.
The committee was set up primarily to deal with larger-scale disputes within smaller Wikis and to enforce the Universal Code of Conduct across the various projects; they are expected to begin hearing cases shortly. Further information can be found on the U4C announcements page.
The full results of the U4C elections can be viewed here. This cycle had already been covered in the 22 July issue of The Signpost. – —S
The WMF releases two new bulletins for August and September
[edit]The Wikimedia Foundation published their bulletins for late August and early September. Among other news, they covered the new WMF Global Advocacy team, which was sworn in back in August, a public survey intended to better understand WikiProjects, the recent disbandment of the MCDC and the WMF Board of Trustees election, which is currently in its scrutiny phase.
It was also mentioned that the WMF will briefly switch the traffic between its data centers for maintenance purposes on 25 September, starting at 15:00 UTC. A banner will be displayed on all Wikis 30 minutes before the start of the operation, during which users will be able to read, but not edit the sites for up to an hour. More information on the server switch can be found here.
Editors may also be interested in testing for the Charts Extension and the Alt Text experiment on the iOS app, the codified new API policy, or the WMF's newest update on Movement Strategy Grants (Spoilers: it focuses on Hubs). —S, O
Brief notes
[edit]
- CEO of the WMF opens up on the outcome of the Movement Charter vote: Maryana Iskander, the current CEO of the Wikimedia Foundation, recently published an e-mail, cosigned by BoT members Nataliia Tymkiv and Dariusz Jemielniak, responding to the outcomes of the discussion about the Movement Charter and thanking everyone who had been engaging with the WMF and the Trustees "with a spirit of generosity, openness, and collective problem-solving".
- Annual reports: Odia Wikimedians User Group, Hausa Wikimedians User Group, WikiClassics User Group.
- Milestones: The following Wikimedia projects reached milestones in August and September 2024:
- Wikipedia articles
- 1,000 articles: Dusun Wikipedia
- 10,000 articles: Gilaki Wikipedia, Dagbani Wikipedia
- 50,000 articles: Ido Wikipedia, Hausa Wikipedia
- 2,000,000 articles: Russian Wikipedia
- Anniversaries
- 1 year: Talysh Wikipedia
- 5 years: N'Ko Wikipedia
- 15 years: Mirandese Wikipedia, Western Punjabi Wikipedia, Central Kurdish Wikipedia
- 20 years: Belarusian Classical Wikipedia
- Wikipedia articles
- New administrators: The Signpost welcomes the English Wikipedia's newest administrators, asilvering and Significa liberdade. The former's request for adminship passed on 6 September, with over 99% support, whereas the latter got promoted on 21 September, with roughly 83.5% support.
- But not enough?: Several new low points in the count of active administrators were reached, culminating with 419 on 16 September, an amount that surpassed minima reported in The Signpost as recently as the prior issue. 2024 has only 9 admins elected by September, quite near the lowest yearly count since the inception of the project. Only 2021 performed definitively worse, with a total of 7 new admins by year-end.
- Global bans:
- Flamelai: This Hong Kong-based user was globally banned on 11 September, after being found to be involved in "alleged acts of trolling, doxxing and intimidation" against Hong Kong journalists, whose trade union had released an official statement and filed reports to the Hong Kong Police Force. The same user had already been blocked by the English and Japanese Wikipedias back in 2023, following a sockpuppetry-related investigation. The person was also banned from Talk and Wikipedia namespace in Chinese Wikipedia in December 2023.
- Anatoly Shariy, since 12 September.
- Articles for Improvement: This week's Article for Improvement is Human geography. Please be bold in helping improve this article! Next week's Article for Improvement (beginning 30 September 2024) is Currency of Spain.
Are Luddaites defending the English Wikipedia?
In response to the increased prevalence of generative artificial intelligence, some editors of the English Wikipedia have introduced measures to reduce its use within the encyclopedia. Using images generated from text-to-image models on articles is often discouraged, unless the context specifically relates to artificial intelligence. A hardline Luddaite approach has not been adopted by all Wikipedians and AI-generated images are used in some articles in non-AI contexts.
Paintings in medical articles
[edit]The image guidelines generally restrict the use of images that are solely for decorative purposes, as they do not contribute meaningful information or aid the reader in understanding the topic. Despite this restriction, it appears that paintings are permitted to be included in medical articles to display human-made artistic interpretations of medical themes. They offer historical and cultural perspectives related to medical topics.
-

-

-

-
 Venus with a Mirror, by Titian on Body image
Venus with a Mirror, by Titian on Body image -
 The Scream, by Edvard Munch on Anxiety disorder. This painting is regarded as a symbol of the anxiety of the human condition.
The Scream, by Edvard Munch on Anxiety disorder. This painting is regarded as a symbol of the anxiety of the human condition. -
 The Imaginary Illness, by Honoré Daumier on Hypochondriasis
The Imaginary Illness, by Honoré Daumier on Hypochondriasis -
 Man with Delusions of Military Command, by Théodore Géricault on Delusional disorder
Man with Delusions of Military Command, by Théodore Géricault on Delusional disorder -

-
 Melancholia, by Tadeusz Pruszkowski on Anhedonia
Melancholia, by Tadeusz Pruszkowski on Anhedonia -

-
 Dance at Molenbeek, by Pieter Brueghel the Younger on Mass psychogenic illness
Dance at Molenbeek, by Pieter Brueghel the Younger on Mass psychogenic illness
,_The_Nightmare,_1781.jpg)

_edited.jpg)




.jpg)



WikiProject AI Cleanup
[edit]WikiProject AI Cleanup searches for AI-generated images and evaluates their suitability for an article. If any images are deemed inappropriate, they may be removed to ensure that only relevant and suitable images are kept in articles.
-
 Removed from Spicy Fifty, due to a "distracting error" (probably the weird pepper that floats and seems to clip the glass).
Removed from Spicy Fifty, due to a "distracting error" (probably the weird pepper that floats and seems to clip the glass). -
 Removed from Shrinkage (accounting) as a real-life alternative could be used instead.
Removed from Shrinkage (accounting) as a real-life alternative could be used instead. -
 Removed from Kemonā for being unnecessarily explicit.
Removed from Kemonā for being unnecessarily explicit. -
 Removed from Pastoral science fiction for adding nothing and barely resembling a landscape.
Removed from Pastoral science fiction for adding nothing and barely resembling a landscape. -
 Removed from Darul Uloom Deoband for bad anatomy and risk of being mistaken for a contemporary work (the college was founded in 1866).
Removed from Darul Uloom Deoband for bad anatomy and risk of being mistaken for a contemporary work (the college was founded in 1866). -
 Removed from The Moon is made of green cheese because a historical illustration was already used in the article.
Removed from The Moon is made of green cheese because a historical illustration was already used in the article.




.png)

Perhaps the removed "scientific" images are the worst ones, however, even if they only affected one article, Chemotactic drug-targeting:
-
 This is supposedly an amoeba moving; it looks more like a sperm cell, if anything. Amoeboid movement and a flagellum are fundamentally different movement techniques, and this looks much more like the latter. Prompt apparently was "an ameba moving toward a food source through the process of chemotaxis". Chemotaxis is movement in response to chemicals in the surrounding environment and needs a lot more creativity to illustrate.
This is supposedly an amoeba moving; it looks more like a sperm cell, if anything. Amoeboid movement and a flagellum are fundamentally different movement techniques, and this looks much more like the latter. Prompt apparently was "an ameba moving toward a food source through the process of chemotaxis". Chemotaxis is movement in response to chemicals in the surrounding environment and needs a lot more creativity to illustrate. -
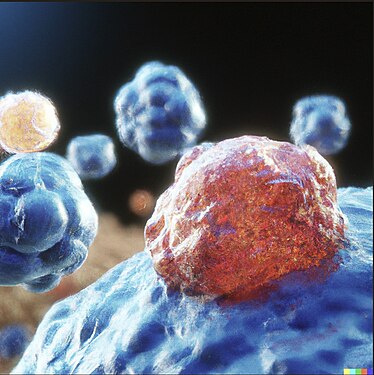 This image inaccurately shows a red tumour on a cell. Cancer cells don't get cancerous tumours on them, they form tumours in aggregate. This is probably based on a cross between a tumour and images of T lymphocytes attacking cancerous cells, but the combination created nonsense. The prompt was apparently a "cancer cell and its abnormal growth", but that's not meant to be growths on the cell itself.
This image inaccurately shows a red tumour on a cell. Cancer cells don't get cancerous tumours on them, they form tumours in aggregate. This is probably based on a cross between a tumour and images of T lymphocytes attacking cancerous cells, but the combination created nonsense. The prompt was apparently a "cancer cell and its abnormal growth", but that's not meant to be growths on the cell itself. -
 Supposedly leukocytes, but leukocytes aren't crystal orbs with vaguely red-blood cell shapes around and inside them. This one is more subtly wrong (it knows there should be something inside, and there's usually some red blood cells mixed in with them in photos...), which arguably makes it more insidious. This just isn't as blatantly bad, making it easier to mistake it as a real image.
Supposedly leukocytes, but leukocytes aren't crystal orbs with vaguely red-blood cell shapes around and inside them. This one is more subtly wrong (it knows there should be something inside, and there's usually some red blood cells mixed in with them in photos...), which arguably makes it more insidious. This just isn't as blatantly bad, making it easier to mistake it as a real image.



It may also be worth considering what kind of AI art is being left in articles by the WikiProject:
-
 Advertisement for "Willy's Chocolate Experience", a disastrous event in Glasgow, Scotland that used AI for all its promotional material. Without cropping out the fake words. A pasadise of sweet teats, indeed!
Advertisement for "Willy's Chocolate Experience", a disastrous event in Glasgow, Scotland that used AI for all its promotional material. Without cropping out the fake words. A pasadise of sweet teats, indeed! -
 These somewhat deformed buildings are apparently typical of ways the meme/hoax country of Listenbourg was depicted using... well, AI images.
These somewhat deformed buildings are apparently typical of ways the meme/hoax country of Listenbourg was depicted using... well, AI images.


AI-generated images on Wikipedia articles in non-AI contexts
[edit]- Note: The following section is accurate as of the day before publication.
Policies vary between different language versions of Wikipedia. Differences in opinion among Wikipedians have resulted in the inclusion of text-to-image model-generated images on several Wikipedias, including the English Wikipedia. Many Wikipedias use Wikidata to automatically display images, which takes place beyond the scope of local projects.
-
![22nd century [ro] on the Romanian Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/5/58/Cyborg_blue_neon_background.png/393px-Cyborg_blue_neon_background.png) 22nd century [ro] on the Romanian Wikipedia
22nd century [ro] on the Romanian Wikipedia -
![Abchanchu [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/a/a1/Abchanchu.png/375px-Abchanchu.png)
-
![Afanc [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/8/86/Afanc.jpg/375px-Afanc.jpg)
-
![Anachronism [no] on the Norwegian Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Abraham_Lincoln_at_Air_Force_One.jpg/375px-Abraham_Lincoln_at_Air_Force_One.jpg) Anachronism [no] on the Norwegian Wikipedia
Anachronism [no] on the Norwegian Wikipedia -
![Archimedes [ar] on the Arabic Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/0/00/%D8%B3%D9%82%D8%B1%D8%A7%D8%B7_%D8%A8%D9%88%D8%A7%D8%B3%D8%B7%D8%A9_%D8%A7%D9%84%D8%B0%D9%83%D8%A7%D8%A1_%D8%A7%D9%84%D8%A7%D8%B5%D8%B7%D9%86%D8%A7%D8%B9%D9%8A.png/375px-%D8%B3%D9%82%D8%B1%D8%A7%D8%B7_%D8%A8%D9%88%D8%A7%D8%B3%D8%B7%D8%A9_%D8%A7%D9%84%D8%B0%D9%83%D8%A7%D8%A1_%D8%A7%D9%84%D8%A7%D8%B5%D8%B7%D9%86%D8%A7%D8%B9%D9%8A.png) Archimedes [ar] on the Arabic Wikipedia
Archimedes [ar] on the Arabic Wikipedia -
 Arcturians (New Age) on the English Wikipedia
Arcturians (New Age) on the English Wikipedia -
 Artificial planet on the English Wikipedia
Artificial planet on the English Wikipedia -
![Battle of Dhu al-Qassah [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/1/16/History_of_the_Arab_Conquest_01.png/375px-History_of_the_Arab_Conquest_01.png) Battle of Dhu al-Qassah [fr] on the French Wikipedia
Battle of Dhu al-Qassah [fr] on the French Wikipedia -
![Chuan Ralla [an] on the Aragonese Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/2/27/Chuan_Ralla.png/500px-Chuan_Ralla.png) Chuan Ralla [an] on the Aragonese Wikipedia
Chuan Ralla [an] on the Aragonese Wikipedia -
![Cleopatra [cs] on the Czech Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/b/b2/AI-Generated_Interpretation_of_Cleopatra_VII.jpg/375px-AI-Generated_Interpretation_of_Cleopatra_VII.jpg)
-
![Climate fiction [fr][uk] on the French and Ukrainian Wikipedias](//upload.wikimedia.org/wikipedia/commons/thumb/b/b3/Cyberpunk_city_with_not_enough_funds_to_protect_against_the_rising_sea%2C_using_the_polluted_water_for_cooler_air.jpg/375px-Cyberpunk_city_with_not_enough_funds_to_protect_against_the_rising_sea%2C_using_the_polluted_water_for_cooler_air.jpg)
-
![Colonization of Mars [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/8/86/A_city_on_Mars_under_a_glass_dome_with_forests%2C_fields%2C_lakes%2C_houses.jpg/375px-A_city_on_Mars_under_a_glass_dome_with_forests%2C_fields%2C_lakes%2C_houses.jpg) Colonization of Mars [fr] on the French Wikipedia
Colonization of Mars [fr] on the French Wikipedia -
![Cosso [gl] on the Galician Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Cosso_%28deus%29_-_IA_Midjourney_versi%C3%B3n_1.png/375px-Cosso_%28deus%29_-_IA_Midjourney_versi%C3%B3n_1.png)
-
![Cyberpunk [hu] on the Hungarian Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/2/20/City_Scene_in_the_style_of_Blade_Runner_01.jpg/375px-City_Scene_in_the_style_of_Blade_Runner_01.jpg)
-
![Dagon [he] on the Hebrew Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/StupendousMonsterOfNightmares.png/375px-StupendousMonsterOfNightmares.png)
-
![Danmei [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Two_danmei_husbands.jpg/375px-Two_danmei_husbands.jpg)
-
Darul Uloom Deoband [ks] on the Kashmiri Wikipedia
-
![Dystopia [es] on the Spanish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/1/12/Dystopia.png/375px-Dystopia.png)
-
![Global catastrophic risk [ha] on the Hausa Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/8/87/Post-apocalyptic_landscape_on_an_industrial_exoplanet_%28recently_collapsed_civilization%29.jpg/375px-Post-apocalyptic_landscape_on_an_industrial_exoplanet_%28recently_collapsed_civilization%29.jpg) Global catastrophic risk [ha] on the Hausa Wikipedia
Global catastrophic risk [ha] on the Hausa Wikipedia -
![Golem [es] on the Spanish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/0/0e/AI_golem_waiting_for_tasks_and_providing_advice.jpg/375px-AI_golem_waiting_for_tasks_and_providing_advice.jpg)
-
![The Great God Pan [he] on the Hebrew Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/c/ca/YoungGirlInWhitesSittingInLaboratory.png/375px-YoungGirlInWhitesSittingInLaboratory.png) The Great God Pan [he] on the Hebrew Wikipedia
The Great God Pan [he] on the Hebrew Wikipedia -
![Gwyn ap Nudd [fr] on the French Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/2/2c/Gwynn_ap_Nudd.jpg/229px-Gwynn_ap_Nudd.jpg) Gwyn ap Nudd [fr] on the French Wikipedia
Gwyn ap Nudd [fr] on the French Wikipedia -
![Invisible religion [cs] on the Czech Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/0/0a/Invisible_Religion_Drawing_AI.jpg/375px-Invisible_Religion_Drawing_AI.jpg) Invisible religion [cs] on the Czech Wikipedia
Invisible religion [cs] on the Czech Wikipedia -
![Iratxoak [ca] on the Catalan Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Galtzagorri_%28euskal_mitologia%29_-_Midjourney_AI_bertsioa.png/336px-Galtzagorri_%28euskal_mitologia%29_-_Midjourney_AI_bertsioa.png)
-
![John F. Kennedy [rw] on the Kinyarwanda Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/a/a1/John_F_Kennedy_in_watercolour.png/375px-John_F_Kennedy_in_watercolour.png) John F. Kennedy [rw] on the Kinyarwanda Wikipedia
John F. Kennedy [rw] on the Kinyarwanda Wikipedia -
![LHS 1140 b [ru] on the Russian Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Possible_depiction_of_LHS_1140_b_landscape_with_black_grass_and_red_starlight.jpg/375px-Possible_depiction_of_LHS_1140_b_landscape_with_black_grass_and_red_starlight.jpg) LHS 1140 b [ru] on the Russian Wikipedia
LHS 1140 b [ru] on the Russian Wikipedia -
![Mikelats [ca][fr] on the Catalan and French Wikipedias](//upload.wikimedia.org/wikipedia/commons/thumb/6/69/Mikelats_%28euskal_mitologia%29_-_Midjourney_AI_bertsioa.png/375px-Mikelats_%28euskal_mitologia%29_-_Midjourney_AI_bertsioa.png)
-
![Mooring [sv] on the Swedish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/1/1f/Ang%C3%B6ring.jpg/375px-Ang%C3%B6ring.jpg)
-
 Pastoral science fiction on the English Wikipedia
Pastoral science fiction on the English Wikipedia -
![Preiddeu Annwfn [ru] on the Russian Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Kaer_sidi.jpg/275px-Kaer_sidi.jpg) Preiddeu Annwfn [ru] on the Russian Wikipedia
Preiddeu Annwfn [ru] on the Russian Wikipedia -
![Raposa do aire [gl] on the Galician Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/3/38/A_raposa_de_Mor%C3%A1s.jpg/375px-A_raposa_de_Mor%C3%A1s.jpg) Raposa do aire [gl] on the Galician Wikipedia
Raposa do aire [gl] on the Galician Wikipedia -
![Religious delusion [nl] on the Dutch Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/f/f7/A_sign_from_God.png/375px-A_sign_from_God.png) Religious delusion [nl] on the Dutch Wikipedia
Religious delusion [nl] on the Dutch Wikipedia -
![Rendlesham Forest incident [es] on the Spanish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Rendlesham_Forest_UFO_incident_digital_CCBY_artwork.jpg/375px-Rendlesham_Forest_UFO_incident_digital_CCBY_artwork.jpg) Rendlesham Forest incident [es] on the Spanish Wikipedia
Rendlesham Forest incident [es] on the Spanish Wikipedia -
![Science fantasy [eu][es] on the Basque and Spanish Wikipedias](//upload.wikimedia.org/wikipedia/commons/thumb/2/20/An_elbish_city_on_an_exoplanet_%28science_fantasy%29.jpg/375px-An_elbish_city_on_an_exoplanet_%28science_fantasy%29.jpg)
-
![Security hacker [ar][es][he][ks][ko] on the Arabic, Spanish, Hebrew, Kashmiri, and Korean Wikipedias](//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Anonymous_Hacker.png/375px-Anonymous_Hacker.png)
-
![Silurian hypothesis [nl] on the Dutch Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Silurian_hypothesis.jpg/375px-Silurian_hypothesis.jpg) Silurian hypothesis [nl] on the Dutch Wikipedia
Silurian hypothesis [nl] on the Dutch Wikipedia -
![Silurian hypothesis [fr][es] on the French and Spanish Wikipedias](//upload.wikimedia.org/wikipedia/commons/thumb/3/3c/The_annihilated_civilization.jpg/375px-The_annihilated_civilization.jpg)
-
 Space travel in science fiction, recently removed from the English Wikipedia
Space travel in science fiction, recently removed from the English Wikipedia -
![Sundiata Keita [es], recently removed from the Spanish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/5/56/Emperor_Sundiata.png/300px-Emperor_Sundiata.png) Sundiata Keita [es], recently removed from the Spanish Wikipedia
Sundiata Keita [es], recently removed from the Spanish Wikipedia -
![Technosignature [es] on the Spanish Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/A_colonized_comet_with_a_long_abandoned_reception_center_above_underground_facility_%28AI_art%29.jpg/375px-A_colonized_comet_with_a_long_abandoned_reception_center_above_underground_facility_%28AI_art%29.jpg) Technosignature [es] on the Spanish Wikipedia
Technosignature [es] on the Spanish Wikipedia -
 Twin paradox on the English Wikipedia
Twin paradox on the English Wikipedia -
![Unicorn [pt] on the Portuguese Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/8/87/Unicorn2024.png/375px-Unicorn2024.png)
-
![A Voyage to Arcturus [he] on the Hebrew Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/d/dc/VoyageToArcturusSeance.png/375px-VoyageToArcturusSeance.png) A Voyage to Arcturus [he] on the Hebrew Wikipedia
A Voyage to Arcturus [he] on the Hebrew Wikipedia -
 World Poetry Day on many Wikipedias
World Poetry Day on many Wikipedias -
![Xan Quinto [ca] on the Catalan Wikipedia](//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Xan_Quinto_-_IA_Midjourney_versi%C3%B3n_1.png/305px-Xan_Quinto_-_IA_Midjourney_versi%C3%B3n_1.png) Xan Quinto [ca] on the Catalan Wikipedia
Xan Quinto [ca] on the Catalan Wikipedia
![22nd century [ro] on the Romanian Wikipedia](/wiki/File:Cyborg_blue_neon_background.png)
![Abchanchu [fr] on the French Wikipedia](/wiki/File:Abchanchu.png)
![Afanc [fr] on the French Wikipedia](/wiki/File:Afanc.jpg)
![Anachronism [no] on the Norwegian Wikipedia](/wiki/File:Abraham_Lincoln_at_Air_Force_One.jpg)
![Archimedes [ar] on the Arabic Wikipedia](/wiki/File:%D8%B3%D9%82%D8%B1%D8%A7%D8%B7_%D8%A8%D9%88%D8%A7%D8%B3%D8%B7%D8%A9_%D8%A7%D9%84%D8%B0%D9%83%D8%A7%D8%A1_%D8%A7%D9%84%D8%A7%D8%B5%D8%B7%D9%86%D8%A7%D8%B9%D9%8A.png)


![Battle of Dhu al-Qassah [fr] on the French Wikipedia](/wiki/File:History_of_the_Arab_Conquest_01.png)
![Chuan Ralla [an] on the Aragonese Wikipedia](/wiki/File:Chuan_Ralla.png)
![Cleopatra [cs] on the Czech Wikipedia](/wiki/File:AI-Generated_Interpretation_of_Cleopatra_VII.jpg)
![Climate fiction [fr][uk] on the French and Ukrainian Wikipedias](/wiki/File:Cyberpunk_city_with_not_enough_funds_to_protect_against_the_rising_sea,_using_the_polluted_water_for_cooler_air.jpg)
![Colonization of Mars [fr] on the French Wikipedia](/wiki/File:A_city_on_Mars_under_a_glass_dome_with_forests,_fields,_lakes,_houses.jpg)
![Cosso [gl] on the Galician Wikipedia](/wiki/File:Cosso_(deus)_-_IA_Midjourney_versi%C3%B3n_1.png)
![Cyberpunk [hu] on the Hungarian Wikipedia](/wiki/File:City_Scene_in_the_style_of_Blade_Runner_01.jpg)
![Dagon [he] on the Hebrew Wikipedia](/wiki/File:StupendousMonsterOfNightmares.png)
![Danmei [fr] on the French Wikipedia](/wiki/File:Two_danmei_husbands.jpg)
![Dystopia [es] on the Spanish Wikipedia](/wiki/File:Dystopia.png)
![Global catastrophic risk [ha] on the Hausa Wikipedia](/wiki/File:Post-apocalyptic_landscape_on_an_industrial_exoplanet_(recently_collapsed_civilization).jpg)
![Golem [es] on the Spanish Wikipedia](/wiki/File:AI_golem_waiting_for_tasks_and_providing_advice.jpg)
![The Great God Pan [he] on the Hebrew Wikipedia](/wiki/File:YoungGirlInWhitesSittingInLaboratory.png)
![Gwyn ap Nudd [fr] on the French Wikipedia](/wiki/File:Gwynn_ap_Nudd.jpg)
![Invisible religion [cs] on the Czech Wikipedia](/wiki/File:Invisible_Religion_Drawing_AI.jpg)
![Iratxoak [ca] on the Catalan Wikipedia](/wiki/File:Galtzagorri_(euskal_mitologia)_-_Midjourney_AI_bertsioa.png)
![John F. Kennedy [rw] on the Kinyarwanda Wikipedia](/wiki/File:John_F_Kennedy_in_watercolour.png)
![LHS 1140 b [ru] on the Russian Wikipedia](/wiki/File:Possible_depiction_of_LHS_1140_b_landscape_with_black_grass_and_red_starlight.jpg)
![Mikelats [ca][fr] on the Catalan and French Wikipedias](/wiki/File:Mikelats_(euskal_mitologia)_-_Midjourney_AI_bertsioa.png)
![Mooring [sv] on the Swedish Wikipedia](/wiki/File:Ang%C3%B6ring.jpg)

![Preiddeu Annwfn [ru] on the Russian Wikipedia](/wiki/File:Kaer_sidi.jpg)
![Raposa do aire [gl] on the Galician Wikipedia](/wiki/File:A_raposa_de_Mor%C3%A1s.jpg)
![Religious delusion [nl] on the Dutch Wikipedia](/wiki/File:A_sign_from_God.png)
![Rendlesham Forest incident [es] on the Spanish Wikipedia](/wiki/File:Rendlesham_Forest_UFO_incident_digital_CCBY_artwork.jpg)
![Science fantasy [eu][es] on the Basque and Spanish Wikipedias](/wiki/File:An_elbish_city_on_an_exoplanet_(science_fantasy).jpg)
![Security hacker [ar][es][he][ks][ko] on the Arabic, Spanish, Hebrew, Kashmiri, and Korean Wikipedias](/wiki/File:Anonymous_Hacker.png)
![Silurian hypothesis [nl] on the Dutch Wikipedia](/wiki/File:Silurian_hypothesis.jpg)
![Silurian hypothesis [fr][es] on the French and Spanish Wikipedias](/wiki/File:The_annihilated_civilization.jpg)

![Sundiata Keita [es], recently removed from the Spanish Wikipedia](/wiki/File:Emperor_Sundiata.png)
![Technosignature [es] on the Spanish Wikipedia](/wiki/File:A_colonized_comet_with_a_long_abandoned_reception_center_above_underground_facility_(AI_art).jpg)

![Unicorn [pt] on the Portuguese Wikipedia](/wiki/File:Unicorn2024.png)
![A Voyage to Arcturus [he] on the Hebrew Wikipedia](/wiki/File:VoyageToArcturusSeance.png)

![Xan Quinto [ca] on the Catalan Wikipedia](/wiki/File:Xan_Quinto_-_IA_Midjourney_versi%C3%B3n_1.png)
{kind=link}
{kind=link}
Article-writing AI is less "prone to reasoning errors (or hallucinations)" than human Wikipedia editors
A monthly overview of recent academic research about Wikipedia and other Wikimedia projects, also published as the Wikimedia Research Newsletter.
"Wikicrow" AI less "prone to reasoning errors (or hallucinations)" than human Wikipedia editors when writing gene articles
[edit]A preprint titled "Language Agents Achieve Superhuman Synthesis of Scientific Knowledge"[1] introduces
"PaperQA2, a frontier language model agent optimized for improved factuality, [which] matches or exceeds subject matter expert performance on three realistic [research] literature research tasks. PaperQA2 writes cited, Wikipedia-style summaries of scientific topics that are significantly more accurate than existing, human-written Wikipedia articles."
It was published by "FutureHouse", a San-Francisco-based nonprofit working on "Automating scientific discovery" (with a focus on biology). FutureHouse was launched last year with funding from former Google CEO Eric Schmidt (at which time it was anticipated it would spend about $20 million by the end of 2024). Generating Wikipedia-like articles about science topics is only one of the applications of "PaperQA2, FutureHouse's scientific RAG [retrieval-augmented generation] system", which is designed to aid researchers. (For example, FutureHouse also recently launched a website called "Has Anyone", described as a "minimalist AI tool to search if anyone has ever researched a given topic.")
In more detail, the researchers "engineered a system called WikiCrow, which generates cited Wikipedia-style articles about human protein-coding genes by combining several PaperQA2 calls on topics such as the structure, function, interactions, and clinical significance of the gene." Each call contributes a section of the resulting article (somewhat similar to another recent system, see our review: "STORM: AI agents role-play as 'Wikipedia editors' and 'experts' to create Wikipedia-like articles"). The prompts include the instruction to "Write in the style of a Wikipedia article, with concise sentences and coherent paragraphs".
With an average cost of $5.50, the generated articles tended to be longer than their Wikipedia counterparts and had higher quality, at least according to the paper's evaluation method:
We used WikiCrow to generate 240 articles on genes that already have non-stub Wikipedia articles to have matched comparisons. WikiCrow articles averaged 1219.0 ± 275.0 words (mean ± SD, N = 240), longer than the corresponding Wikipedia articles (889.6 ± 715.3 words). The average article was generated in 491.5 ± 324.0 seconds, and had an average cost of $4.48 ± $1.02 per article (including costs for search and LLM APIs). We compared WikiCrow and Wikipedia on 375 statements sampled from the 240 paired articles. [...] The initial article sampling excluded any Wikipedia articles that were "stubs" or incomplete articles. Statements were then shuffled and given, blinded, to human experts, who graded statements according to whether they were (1) cited and supported; (2) missing a citation; or (3) cited and unsupported. We found that WikiCrow had significantly fewer "cited and unsupported" statements than the paired Wikipedia articles (13.5% vs. 24.9%) (p = 0.0075, χ2 (1), N = 375 for all tests in this section). WikiCrow failed to cite sources at a 3.9x lower rate than human written articles, as only 3.5% of WikiCrow statements were uncited, vs. 13.6% for Wikipedia (p < 0.001). In addition, defining precision for WikiCrow as the ratio of cited and supported statements over all cited statements, we found that WikiCrow displayed significantly higher precision than human-written articles (86.1% vs. 71.2%, p = 0.0013).
For the judgment whether a particular statement was "supported" by the cited references, the concrete question asked to the graders (described as "expert researchers" in the paper) was:
"Is the information correct, as cited? In other words, is the information stated in the sentence correct according to the literature that it cites?"
In addition, among other more detailed instructions, the graders were advised to mark a statement correct as cited even if it was not directly supported by the source, as long as the statement consisted of "broad context" judged to be "undergraduate biology student common knowledge" (akin to an extreme interpretation of WP:BLUE).
The fact that these rating criteria appear to be more liberal than Wikipedia's own, combined with the well-known general reputation of LLMs for generating hallucinations, makes the "WikiCrow displayed significantly higher precision" result rather remarkable. The authors double-checked it by examining the data more closely:
The "cited and unsupported" evaluation category includes both inaccurate statements (e.g. true hallucinations or reasoning errors) and statements that are accurate with inappropriate citations. To investigate the nature of the errors in Wikipedia and WikiCrow further, we manually inspected all reported errors and attempted to classify the issues as follows: reasoning issues, i.e. the written information contradicts, over-extrapolates, or is unsupported by any included citations; attribution issues, i.e. the information is likely supported by another included source, but either the statement does not include the correct citation locally or the source is too broad (e.g. a database portal link); or trivial statements, which are true passages, but overly pedantic or unnecessary [...]. Surprisingly, we found that compared to Wikipedia, WikiCrow had significantly fewer reasoning errors (12 vs. 26, p = 0.0144, χ2 (1), N = 375) but a similar number of attribution errors (10 vs. 16, p = 0.21), suggesting that the improved factuality of WikiCrow over Wikipedia was largely due to improvements in reasoning.
.webp)
The authors caution that this result about Wikipedians "hallucinating" more frequently than AI is specific to their "WikiCrow" system (and the task of writing articles about genes), and must not be generalized to LLMs in general:
Although language models are clearly prone to reasoning errors (or hallucinations), in our task at least they appear to be less prone to such errors than Wikipedia authors or editors. This statement is specific to the agentic RAG setting presented here: language models like GPT-4 on their own, if asked to generate Wikipedia articles, would still be expected to hallucinate at high rates.
A previous, less capable version of the WikiCrow system had already been described in a December 2023 blog post, which discussed the motivation for focusing on the task of writing Wikipedia-like articles about genes in more detail. Rather than seeing it as an arbitrary benchmark demo for their LLM agent system (back then in its earlier version, PaperQA), the authors described it as being motivated by longstanding shortcomings of Wikipedia's gene coverage that are seriously hampering the work of researchers who have come to rely on Wikipedia:
If you've spent time in molecular biology, you have probably encountered the "alphabet soup" problem of genomics. Experiments in genomics uncover lists of genes implicated in a biological process, like MGAT5B and ADGRA3. Researchers turn to tools like Google, Uniprot or Wikipedia to learn more, as the knowledge of 20,000 human genes is too broad for any single human to understand. However, according to our count, only 3,639 of the 19,255 human protein-coding genes recognized by the HGNC have high-quality (non-stub) summaries on [English] Wikipedia; the other 15,616 lack pages or are incomplete stubs. Often, plenty is known about the gene, but no one has taken the time to write up a summary. This is part of a much broader problem today: scientific knowledge is hard to access, and often locked up in impenetrable technical reports. To find out about genes like MGAT5B and ADGRA3, you'd end up sinking hours into reading the primary literature.
[The 2023 version of] WikiCrow is a first step towards automated synthesis of human scientific knowledge. As a first demo, we used WikiCrow to generate drafts of Wikipedia-style articles for all 15,616 of the Human protein-coding genes that currently lack articles or have stubs, using information from full-text articles that we have access to through our academic affiliations. We estimate that this task would have taken an expert human ~60,000 hours total (6.8 working years). By contrast, WikiCrow wrote all 15,616 articles in a few days (about 8 minutes per article, with 50 instances running in parallel), drawing on 14,819,358 pages from 871,000 scientific papers that it identified as relevant in the literature.
These challenges of covering the large number of relevant genes are not news to Wikipedians working in this area. Back in 2011, several papers in a special issue of Nucleic Acids Research on databases had explored Wikipedia as a database for structured biological data, e.g. asking "how to get scientists en masse to edit articles" in this area, and presenting English Wikipedia's "Gene Wiki" taskforce (which is currently inactive). In a 2020 article in eLife, a group of 30 researchers and Wikidata contributors similarly "describe[d] the breadth and depth of the biomedical knowledge contained within Wikidata," including its coverage of genes in general ("Wikidata contains items for over 1.1 million genes and 940 thousand proteins from 201 unique taxa") and human genetic variants ("Wikidata currently contains 1502 items corresponding to human genetic variants, focused on those with a clear clinical or therapeutic relevance").[2] But it seems that at least from the point of view of the FutureHouse researchers, Wikidata's gene coverage is not a substitute for Wikipedia's, perhaps because it does not offer the same kind of factual coverage (see also the review of a related dissertation below).
The current paper is not peer-reviewed, but conveys credibility by disclosing ample detail about the methodology for building and evaluating the PaperQA2 and WikiCrow systems (also in an accompanying technical blog post), and by releasing the underlying source code and data. The PaperQA2 system is available as an open-source software package. (This includes a "Setting to emulate the Wikipedia article writing used in our WikiCrow publication". However, the paper cautions that the released version does not include some additional tools that were used, and in particular does not provide "access to non-local full-text literature searches", which are "often bound by licensing agreements".) The generated articles are available online in rendered form and as Markdown source (see full list below, with links to their Wikipedia counterparts for comparison). The annotated expert ratings have been published as well.
The authors acknowledge "previous work on unconstrained document summarization, where the document must be found and then summarized, and even writing Wikipedia-style articles with RAG" (i.e. the aforementioned STORM project). But they highlight that
"These studies have not compared directly against Wikipedia with human evaluation. Instead, they used either LLMs to judge or [like STORM] compared ROGUE (text overlap) against ground-truth summaries. Here, we measure directly against human-generated Wikipedia with subject [matter] expert grading."
The "crow" moniker (already used in a predecessor project called "ChemCrow",[supp 1] an LLM agent working on chemistry tasks) is inspired by the fact that "Crows can talk – like a parrot – but their intelligence lies in tool use."
Using Wikipedia's categories and list pages to build a knowledge graph separate from Wikidata
[edit]From the abstract of a dissertation titled "Exploiting semi-structured information in Wikipedia for knowledge graph construction":[3]
"[...] we address three main challenges in the field of automated knowledge graph construction using semi-structured data in Wikipedia as a data source. To create an ontology with expressive and fine-grained types, we present an approach that extracts a large-scale general-purpose taxonomy from categories and list pages in Wikipedia. We enhance the taxonomy's classes with axioms explicating their semantics. To increase the coverage of long-tail entities in knowledge graphs, we describe a pipeline of approaches that identify entity mentions in Wikipedia listings, integrate them into an existing knowledge graph, and enrich them with additional facts derived from the extraction context. As a result of applying the above approaches to semi-structured data in Wikipedia, we present the knowledge graph CaLiGraph. The graph describes more than 13 million entities with an ontology containing almost 1.3 million classes. To judge the value of CaLiGraph for practical tasks, we introduce a framework that compares knowledge graphs based on their performance on downstream tasks. We find CaLiGraph to be a valuable addition to the field of publicly available general-purpose knowledge graphs."
Why would one want to use Wikipedia as a source of structured data and build a new knowledge graph when Wikidata already exists? First, the thesis argues that Wikidata — even though it has surpassed other public knowledge graphs in the number of entitities — is still very incomplete, especially when it comes to information about long-tail topics:
"The trend of entities added to publicly available KGs in recent years indicates they are far from complete. The number of entities in Wikidata [195], for example, grew by 26% in the time from October 2020 (85M) to October 2023 (107M) [206]. Wikidata describes the largest number of entities and comprises – in terms of entities – other public KGs to a large extent [66]. Consequently, this challenge of incompleteness applies to all public KGs, particularly when it comes to less popular entities [44]. [...]
On the other hand, an automated process for extracting structured information from Wikipedia may not yet be reliable enough to import the result directly without manual review:
While the performance of Open Information Extraction (OIE) systems (i.e., systems that extract information from general web text) has improved in recent years [159, 97, 112], the quality of extracted information has not yet reached a level where integration into public KGs like Wikidata or DBpedia [104] should be done without further filtering. [...]
[...] first "picking low-hanging fruit" by focusing on premium sources like Wikipedia to build a high-quality KG is crucial as it can serve as a solid foundation for approaches that target more challenging data sources. The extracted information may then be used as an additional anchor to make sense of less structured data.
Chapter 3 ("Knowledge Graphs on the Web") contains detailed comparisons of Wikidata with other public knowledge graphs, with observations including the following:
The main focus of DBpedia is on persons (and their careers), as well as places, works, and species. Wikidata also strongly focuses on works (mainly due to the import of entire bibliographic datasets), while Cyc, BabelNet and NELL show a more diverse distribution. [...]
[...] Wikidata has the largest number of instances and the largest detail level in most classes. However, there are differences from class to class. While Wikidata contains a large number of works, YAGO is a good source of events. NELL often has fewer instances, but a larger level of detail, which can be explained by its focus on more prominent instances.
Wikidata contains about twice as many persons as DBpedia and YAGO [..., which] contain almost no persons which are not contained in Wikidata. In conclusion, combining Wikidata with DBpedia or YAGO for better coverage of the Person class would not be beneficial"
(see also an earlier paper co-authored by the author that was titled "Knowledge Graphs on the Web -- an Overview")
Briefly
[edit]- See the page of the monthly Wikimedia Research Showcase for videos and slides of past presentations.
Other recent publications
[edit]Other recent publications that could not be covered in time for this issue include the items listed below. Contributions, whether reviewing or summarizing newly published research, are always welcome.
"Refining Wikidata Taxonomy using Large Language Models"
[edit]_to_entity_(Q35120)_before_refinement.png) |
_to_entity_(Q35120)_after_refinement.png)
|
| A Wikidata taxonomy (from "city or town" to "entity") before and after refinement | |
From the abstract:[4]
"Wikidata is known to have a complex taxonomy, with recurrent issues like the ambiguity between instances and classes, the inaccuracy of some taxonomic paths, the presence of cycles, and the high level of redundancy across classes. Manual efforts to clean up this taxonomy are time-consuming and prone to errors or subjective decisions. We present WiKC, a new version of Wikidata taxonomy cleaned automatically using a combination of Large Language Models (LLMs) and graph mining techniques."
From the "Evaluation" section:
"As expected, WiKC is much simpler and much more concise than Wikidata taxonomy. Compared to WiKC, Wikidata taxonomy has a factor higher than 200 in the number of classes, and a factor higher than 10 in the average number of paths from an instance to the root class entity (Q35120)."
"WiKC consistently outperforms Wikidata across all depth ranges. WiKC shows significant accuracy gains at deeper levels (depth 10 or more), suggesting that WiKC has resolved many inconsistency issues in the lower levels of the Wikidata taxonomy."
"Psychiq and Wwwyzzerdd: Wikidata completion using Wikipedia"
[edit]From the abstract:[5]
"Hundreds of thousands of articles on English Wikipedia have zero or limited meaningful structure on Wikidata. Much work has been done in the literature to partially or fully automate the process of completing knowledge graphs, but little of it has been practically applied to Wikidata. This paper presents two interconnected practical approaches to speeding up the Wikidata completion task. The first is Wwwyzzerdd, a browser extension that allows users to quickly import statements from Wikipedia to Wikidata. Wwwyzzerdd has been used to make over 100 thousand edits to Wikidata. The second is Psychiq, a new model for predicting instance and subclass statements based on English Wikipedia articles. [...] One initial use is integrating the Psychiq model into the Wwwyzzerdd browser extension."
"Bridging Background Knowledge Gaps in Translation with Automatic Explicitation"
[edit]From the paper:[6]
"Translations help people understand content written in another language. However, even correct literal translations do not fulfill that goal when people lack the necessary background to understand them. Professional translators incorporate explicitations to explain the missing context by considering cultural differences between source and target audiences. [...] For example, the name “Dominique de Villepin” may be well known in French community while totally unknown to English speakers in which case the translator may detect this gap of background knowledge between two sides and translate it as “the former French Prime Minister Dominique de Villepin” instead of just “Dominique de Villepin”. [...]
This work introduces techniques for automatically generating explicitations, motivated by WIKIEXPL, a dataset that we collect from Wikipedia and annotate with human translators. [...]
Our generation is grounded in Wikidata and Wikipedia—rather than free-form text generation—to prevent hallucinations and to control length or the type of explanation. For SHORT explicitations, we fetch a word from instance of or country of from Wikidata [...]. For MID, we fetch a description of the entity from Wikidata [...]. For LONG type, we fetch three sentences from the first paragraph of Wikipedia."
"Relevant Entity Selection: Knowledge Graph Bootstrapping [from Wikidata] via Zero-Shot Analogical Pruning"
[edit]From the abstract:[7]
"Knowledge Graph Construction (KGC) can be seen as an iterative process starting from a high quality nucleus that is refined by knowledge extraction approaches in a virtuous loop. Such a nucleus can be obtained from knowledge existing in an open KG like Wikidata. However, due to the size of such generic KGs, integrating them as a whole may entail irrelevant content and scalability issues. We propose an analogy-based approach that starts from seed entities of interest in a generic KG, and keeps or prunes their neighboring entities. We evaluate our approach on Wikidata through two manually labeled datasets that contain either domain-homogeneous or -heterogeneous seed entities."
"Assembling Hyperpop: Genre Formation on Wikipedia"
[edit]From the abstract:[8]
"By analyzing the edit history of Wikipedia’s ‘hyperpop’ page, we locate ongoing debates, controversies, and contestations that point to shaping forces around online genre formation. These potentially have a huge impact on how hyperpop is understood both inside and outside of the music community. In locating the most active editors of the hyperpop Wikipedia page and scrutinizing their edit histories as well as the discussions on the hyperpop page itself, we uncovered debates about artistic notability, biases toward specific sources, and attempts at associating or dissociating musical genre from non-musical identities (such as race, gender, and nationality)."
"After all, who invented the airplane? Multilingualism and grassroots knowledge production on Wikipedia"
[edit]From the abstract:[9]
"Paradoxically, in each language [English/French/Portuguese Wikipedia], the airplane has a different inventor. Through online ethnography, this article explores the multilingual landscape of Wikipedia, looking not only at languages, but also at language varieties, and unpacking the intricate connections between language, country, and nationality in grassroots knowledge production online."
.jpg)
References
[edit]- ^ Michael D. Skarlinski and Sam Cox and Jon M. Laurent and James D. Braza and Michaela Hinks and Michael J. Hammerling and Manvitha Ponnapati and Samuel G. Rodriques and Andrew D. White (2024), Language Agents Achieve Superhuman Synthesis of Scientific Knowledge, San Francisco, CA: FutureHouse / Code / Data (generated articles)
- ^ Waagmeester, Andra; Stupp, Gregory; Burgstaller-Muehlbacher, Sebastian; Good, Benjamin M; Griffith, Malachi; Griffith, Obi L; Hanspers, Kristina; Hermjakob, Henning; Hudson, Toby S; Hybiske, Kevin; Keating, Sarah M; Manske, Magnus; Mayers, Michael; Mietchen, Daniel; Mitraka, Elvira; Pico, Alexander R; Putman, Timothy; Riutta, Anders; Queralt-Rosinach, Nuria; Schriml, Lynn M; Shafee, Thomas; Slenter, Denise; Stephan, Ralf; Thornton, Katherine; Tsueng, Ginger; Tu, Roger; Ul-Hasan, Sabah; Willighagen, Egon; Wu, Chunlei; Su, Andrew I (2020-03-17). "Wikidata as a knowledge graph for the life sciences". eLife. 9. Peter Rodgers, Chris Mungall (eds.): –52614. doi:10.7554/eLife.52614. ISSN 2050-084X.
{{cite journal}}: CS1 maint: unflagged free DOI (link) - ^ Heist, Nicolas (2024). Exploiting semi-structured information in Wikipedia for knowledge graph construction (Thesis). Universität Mannheim. (dissertation)
- ^ Peng, Yiwen; Bonald, Thomas; Alam, Mehwish (October 2024). "Refining Wikidata Taxonomy using Large Language Models". ACM International Conference on Information and Knowledge Management. Boise, Idaho, United States. doi:10.1145/3627673.3679156. Code/data
- ^ Erenrich, Daniel (2023-01-01). "Psychiq and Wwwyzzerdd: Wikidata completion using Wikipedia". Semantic Web. Preprint (Preprint): 1–14. doi:10.3233/SW-233450. ISSN 1570-0844.
- ^ Han, HyoJung; Boyd-Graber, Jordan Lee; Carpuat, Marine (2023-12-03), Bridging Background Knowledge Gaps in Translation with Automatic Explicitation, arXiv / dataset
- ^ Jarnac, Lucas; Couceiro, Miguel; Monnin, Pierre (2023-10-21). "Relevant Entity Selection: Knowledge Graph Bootstrapping via Zero-Shot Analogical Pruning". Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. CIKM '23. New York, NY, USA: Association for Computing Machinery. pp. 934–944. doi:10.1145/3583780.3615030. ISBN 9798400701245.
 , preprint version:
Jarnac, Lucas; Couceiro, Miguel; Monnin, Pierre (2023-10-21). "Relevant Entity Selection: Knowledge Graph Bootstrapping via Zero-Shot Analogical Pruning". Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. pp. 934–944. doi:10.1145/3583780.3615030.
, preprint version:
Jarnac, Lucas; Couceiro, Miguel; Monnin, Pierre (2023-10-21). "Relevant Entity Selection: Knowledge Graph Bootstrapping via Zero-Shot Analogical Pruning". Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. pp. 934–944. doi:10.1145/3583780.3615030.
- ^ Bates, Eliot; Delphis, Sophie; Moraes, Romulo; Santoli, Julia (2024-09-08). "Assembling Hyperpop: Genre Formation on Wikipedia". Cultural Sociology: 17499755241264905. doi:10.1177/17499755241264905. ISSN 1749-9755.
- ^ Fians, Guilherme (2024-11-01). "After all, who invented the airplane? Multilingualism and grassroots knowledge production on Wikipedia". Language & Communication. 99: 39–51. doi:10.1016/j.langcom.2024.08.001. ISSN 0271-5309.
- Supplementary references:
- ^ M. Bran, Andres; Cox, Sam; Schilter, Oliver; Baldassari, Carlo; White, Andrew D.; Schwaller, Philippe (May 2024). "Augmenting large language models with chemistry tools". Nature Machine Intelligence. 6 (5): 525–535. doi:10.1038/s42256-024-00832-8. ISSN 2522-5839.
Jump in the line, rock your body in time
- This traffic report is adapted from the Top 25 Report, prepared with commentary by Igordebraga, Vestrian24Bio (August 25 to September 14), Ltbdl, and Rahcmander (August 25 to 31), Oltrepier (September 1 to 7), Hubert555 (September 8 to 14).
What's the story, morning glory? (August 25 to 31)
[edit]| Rank | Article | Class | Views | Image | Notes/about |
|---|---|---|---|---|---|
| 1 | Oasis (band) | 1,428,910 | _Oasis_(3617105240).jpg) |
Mancunian brothers Liam Gallagher and Noel Gallagher (plus other musicians that weren't as fond of squabbling) spent the 90s and 2000s making music and fighting each other, with the latter part escalating so much that the brothers broke up their own band in 2009. So what a relief for Oasis fans to know that, in the wake of the 30th anniversary of the band's debut album, Definitely Maybe, a 2025 reunion tour was announced, initially limited to the British Isles, but with hopes that it will expand to other parts of the world, especially as tickets have sold out fairly quickly. The rest of Oasis will include three more past members: guitarists Paul "Bonehead" Arthurs (who played on the band's beloved first two albums and the divisive and overblown third) and Gem Archer (who joined in the tour for the fourth album and remained until the end), and drummer Chris Sharrock (part of the band's doomed final tour). Some members from Noel's side band, the High Flying Birds, will also join in. | |
| 2 | Johnny Gaudreau | 1,067,759 |  |
"Johnny Hockey" was a standout name in the NHL, but sadly his career was cut short at just 31, as he and his brother Matthew (who also played hockey) died after being run over while riding their bikes in New Jersey. An outpour of commotion emerged, including from Gaudreau's current and former teams, as the late winger left behind two young children, while his sister was forced to cancel her wedding. Everyone also hopes the drunk driver who caused the accident faces the consequences. | |
| 3 | Deaths in 2024 | 1,004,696 |  |
You need more time 'Cause your thoughts and words won't last forever more And I'm not sure if it'll ever work out right... | |
| 4 | Stree 2 | 1,002,390 |  |
This Bollywood comedy horror film, the fifth installment in the Maddock Supernatural Universe and a sequel to the first chapter of the series, released on the Indian Independence Day, and has soon become the highest-grossing Hindi film of 2024, as well as the ninth highest-grossing Hindi film of all time. It is also the second highest-grossing Indian film of 2024, behind only Tollywood epic science fiction movie, Kalki 2898 AD. | |
| 5 | Deadpool & Wolverine | 959,740 | .jpg) |
The 34th film in the MCU was first released a few months ago, bridging the franchise with the Fox Universe and becoming the first ever MCU film to receive an R-rating; it has now become the seventh highest grossing film from the franchise, surpassing Iron Man 3. | |
| 6 | Robert F. Kennedy Jr. | 859,701 | _(cropped).jpg) |
Kennedy hasn't fully dropped out of the presidential race — but he's withdrawing his name from most swing states, making sure that he won't affect the electoral vote, but still can be voted for in most states. As of writing, his website says that Kennedy is aiming for 5% or more of the popular vote, as that will qualify him for public funding in future elections. | |
| 7 | Pavel Durov | 857,832 | _(cropped).jpg) |
Anti-establishment, Russian, and a billionaire, Durov is the founder of VK, the so-called "Facebook for Russia", as well as the fifth most-used messaging service, Telegram. Because of the latter, he was arrested in France on August 24, reportedly for failing to remove drug traffickers and child pornographers on the platform. Russia is not happy, although Durov himself left the country in 2014, after refusing to hand over the personal data of Euromaidan protesters in Ukraine to the Federal Security Service. | |
| 8 | Sven-Göran Eriksson | 817,262 | .jpg) |
The Swedish football coach died of pancreatic cancer on August 26, at the age of 76. He was probably best known for managing England's Golden Generation in the 2002 and 2006 FIFA World Cups, but also won lots of national and European titles with the likes of IFK Göteborg, Benfica and Lazio. | |
| 9 | Tulsi Gabbard | 746,047 | _(cropped).jpg) |
Just like #6, another former Democratic Presidential hopeful turned right-leaning Independent, who is now working with Donald Trump. | |
| 10 | Liam Gallagher | 731,595 |  |
After the unceremonious split of #1 in 2009, their lead singer spent five more years with other musicians from the band in side group Beady Eye before pursuing a solo career, which earlier this year included a collaboration with Stone Roses guitarist John Squire in the indicatively titled Liam Gallagher & John Squire. Now, though, the main focus is on the 2025 reunion tour of Oasis. |
Daylight come and me wan' go home (September 1 to 7)
[edit]| Rank | Article | Class | Views | Image | Notes/about |
|---|---|---|---|---|---|
| 1 | Emily Armstrong (musician) | 1,428,603 | .jpg) |
The lead singer of Dead Sara has been enlisted for the revival of a very popular nu metal group (#5) that previously disbanded under tragic conditions.
However, Linkin Park's decision to appoint Armstrong has rapidly faced criticism, due to her perceived support of convicted rapist and disgraced actor Danny Masterson, as well as her ties to the anti-psychiatry Church of Scientology; both are very triggering topics for a considerable part of fans who have been grieving for the loss of late lead singer Chester Bennington, including one of his own children. Armstrong did address her past ties to Masterson, but as of this issue's publication, she has not clarified her status within the Scientology Church, yet. | |
| 2 | Rich Homie Quan | 1,144,320 |  |
On September 5, Dequantes Devontay Lamar, better known as Rich Homie Quan, passed away at the age of 34, with the cause of death being still unclear in spite of an autopsy.
The Atlanta-born and based rapper scored a few hits in the 2010s, like "Type of Way", "Flex (Ooh, Ooh, Ooh)" and the team-up single with Young Thug, "Lifestyle". | |
| 3 | The Greatest of All Time | 1,087,524 | .jpg) |
This Kollywood science fiction action film, starring Thalapathy in his 68th film in a lead role, was released last Thursday.
It is expected to be Vijay's penultimate film (or the last one, depending on his plans to call off his next project), since the actor announced his political entry earlier this year. As a result, his fans did not waste their (presumably last) chance to celebrate the film worldwide: the film grossed ₹126.5 crore (US$15 million) in the opening day global box office, emerging as the second highest-grossing Tamil film in 2024, while also giving the actor two consecutive films to gross over ₹100 crores in the opening day. In the process, the film also set many other records, such as the first South Indian film to be shown in more than 20 locations in Norway, including the iSense hall at Odeon Cinemas etc. | |
| 4 | Deaths in 2024 | 981,764 |  |
When it will be right? I don't know. What it will be like? I don't know. We live in hope of deliverance From the darkness that surrounds us... | |
| 5 | Linkin Park | 967,977 | The tragic death of lead singer Chester Bennington first led to Linkin Park's disbandment back in 2017. However, on September 5, they officially announced a reunion, with original members Bennington and Rob Bourdon being replaced with #1 and Colin Brittain, respectively.
On the same occasion, the band delighted fans further by teasing a new studio album and a six-date arena tour, but public reception grew colder in the following days, as concerning details about the past of new co-vocalist Armstrong surfaced. | ||
| 6 | Indian Airlines Flight 814 | 966,085 |  |
Netflix show IC 814: The Kandahar Hijack recently recalled an incident from 25 years ago, describing how an airplane was hijacked by five terrorists from Harkat-ul-Mujahideen, under support by al-Qaeda (who'd infamously hijack four planes in a single day in 2001), keeping 174 passengers and 11 crewpeople hostage for a week, while stabbing one to death to intimidate everyone else, before releasing them in the Afghan city of Kandahar in exchange for three imprisoned terrorists. Those responsible have never been identified. | |
| 7 | Beetlejuice Beetlejuice | 865,176 | .jpg) |
It's showtime! Yes, the recently released sequel and the 1988 original were directly above each other in views, allowing a proper summoning of The Ghost with the Most. Life (or afterlife, in this case) is funny like that sometimes. Anyway, after a cartoon series and a musical, it was finally time for the devious and hyperactive ghost Betelgeuse to haunt the cinemas again, with Beetlejuice Beetlejuice bringing back director Tim Burton and actors Michael Keaton (Beej himself), Winona Ryder (goth Lydia Deetz, now the host of a supernatural talk show) and Catherine O'Hara (Lydia's stepmom Delia). | |
| 8 | Beetlejuice | 813,131 | |||
| 9 | Deadpool & Wolverine | 774,393 | .jpg) |
Two aggressive Mutants teamed up in a movie full of blood, swearing and multiversal shenanigans, that has recently made over a billion dollars, becoming the second highest-grossing movie of this year, behind only Inside Out 2 (which, in turn, rightfully became the highest-grossing animation ever, overtaking a very unnecessary remake).
On a side note, Marvel Cinematic Universe has returned later this month with the Disney+ show Agatha All Along. | |
| 10 | Emma Navarro | 756,697 | _09.jpg) |
This 23-year-old American tennis player, who won her first title at the Hobart International back in January, has just had her best Grand Slam performance during the US Open at home, where she eventually lost in the semi-finals to Aryna Sabalenka, who then proceeded to win it all over another American, Jessica Pegula. |
There's a calm surrender, to the rush of day (September 8 to 14)
[edit]| Rank | Article | Class | Views | Image | Notes/about |
|---|---|---|---|---|---|
| 1 | James Earl Jones | 3,034,998 |  |
One of the most respected African American actors ever, particularly for that booming voice that spoke iconic lines like "No. I am your father", "Everything the light touches is our kingdom", "Steel isn't strong, boy, flesh is stronger!" and "This is CNN", James Earl Jones had a storied career of nearly seven decades, resulting in him being one of the few who won the EGOT (albeit with an honorary Oscar). Retired ever since starring in Coming 2 America in 2021, he died on September 9, at the age of 93. | |
| 2 | Laura Loomer | 1,434,117 | .jpg) |
Donald Trump's supporters are concerned about all the influence he's receiving from this activist and self-proclaimed "pro-white nationalist" and a "proud Islamophobe". | |
| 3 | Kamala Harris | 1,284,808 | .jpg) |
The vice-president and the Democrats' candidate in the upcoming election, who was on millions of screens at last week's presidential debate. | |
| 4 | The Greatest of All Time | 1,153,526 | .jpg) |
This Kollywood science fiction action film, starring Thalapathy in his 68th film in a lead role, was released last week. Earlier this year, the actor announced his political entry, making this movie his penultimate work ever, thus his fans celebrated it worldwide. The film debuted at the second place at the worldwide box office, behind only #7, on its opening weekend. It also became the second Tamil film to enter the global weekend chart of Comscore, with the other film being the same actor's previous film. The film grossed ₹350 crore (US$42 million) worldwide in its opening week, against a budget of ₹300−400 crore, becoming the the highest-grossing Tamil film of 2024 and the fourth highest-grossing Indian film of 2024. Thalapathy's next and last film has now been announced, and the fans are already preparing for the One Last Dance! | |
| 5 | September 11 attacks | 1,132,328 |  |
23 years have passed since this tragedy took place in three different US locations, where many lost their loved ones due to a terrorist attack masterminded by Al-Qaeda. For those interested, it also marks 23 years since the release of the criminally underrated soundtrack from the famously bad movie by this writer's favourite chanteuse, Mariah Carey. The picture on the left summarizes all of it. | |
| 6 | The Perfect Couple (TV series) | 1,010,108 | _(cropped).jpg) |
This American mystery drama series, which is an adaptation of the 2018 novel of the same name by Elin Hilderbrand and includes Nicole Kidman (pictured) in its cast, premiered on Netflix last week. | |
| 7 | Beetlejuice Beetlejuice | 1,009,928 | _(cropped).JPG) |
36 years later, director Tim Burton and actors Michael Keaton, Winona Ryder and Catherine O'Hara returned to a small Connecticut city haunted by weird ghosts. Filled with Burton's signature aesthetics and many funny moments, including a musical number featuring one of the corniest songs ever written, this movie was warmly received and had an impressive $111 million opening in North America alone, which was already enough to cover its production budget. | |
| 8 | Deaths in 2024 | 999,325 |  |
Given one of the quotes from #1 (better use this song now than when the unnecessary prequel arrives): 'Til we find our place On the path unwinding In the circle The circle of life | |
| 9 | Beetlejuice | 881,184 |  |
The death list interrupted, but with three mentions of his name, "it's showtime"! Fresh off Pee-wee's Big Adventure, in 1988 Tim Burton directed the story of a recently deceased couple trying to scare away two yuppies (and their goth daughter) from their old house, at a certain point bringing in the hyperactive undead maniac the movie is named after. The Geffen Company tried to get a sequel shortly after the movie, with Burton himself thinking about doubling the insanity in Beetlejuice Goes Hawaiian, but Betelgeuse and Lydia Deetz only had a cartoon and a musical adaptation before the proper follow-up listed above. | |
| 10 | Rebel Ridge | 679,584 |  |
This film, starring Aaron Pierre as a former Marine and Don Johnson as the chief of a corrupt police force, was released by Netflix on September 6 to positive reviews. |
Exclusions
[edit]- These lists exclude the Wikipedia main page, non-article pages (such as redlinks), and anomalous entries (such as DDoS attacks or likely automated views). Since mobile view data became available to the Report in October 2014, we exclude articles that have almost no mobile views (5–6% or less) or almost all mobile views (94–95% or more) because they are very likely to be automated views based on our experience and research of the issue. Please feel free to discuss any removal on the Top 25 Report talk page if you wish.
Most edited articles
[edit]For the August 16 – September 16 period, per this database report.
| Title | Revisions | Notes |
|---|---|---|
| Deaths in 2024 | 2083 | Along with the ones mentioned above and a few others from the last Traffic Report, other notable deceased of the period included Phil Donahue, Sid Eudy, Rebecca Cheptegei and Sérgio Mendes. |
| Andrew Jackson and the slave trade in the United States | 1404 | Back in June, user Jengod split from the list of American slave traders this page regarding the seventh U.S. President Andrew Jackson's involvement in slave trading, and has been working on it extensively ever since. |
| India at the 2024 Summer Paralympics | 1392 | For all of India's underperformances at the Olympics, their disabled para-athletes have impressive showings at the Paralympic Games. Just this year in Paris, the country managed to win 29 medals, which is the same amount they have got in the last 52 years of the Olympics! These include seven golds, four of which in athletics and one each in shooting, archery and badminton. |
| List of Kamala Harris 2024 presidential campaign endorsements | 1259 | A laundry list of supporters for the current VP, including Republicans that dislike their own candidate. |
| Great Britain at the 2024 Summer Paralympics | 1149 | Like Greece created the Olympics, Great Britain is the origin of the Paralympics. They're the second most successful nation at the games, behind (no surprise) the United States, and Paris 2024 had them in second place in the medal table, behind only China, with 124 medals, 49 of which golden. |
| 2024 Pacific typhoon season | 1100 | Wikipedia's branch that edits cyclone pages is a very dedicated bunch, as reflected in over 200 Featured Articles. Updates came for the storms formed in the Pacific, the strongest of which was Typhoon Yagi, that hit Southeast Asia and South China in early September. |
| Typhoon Yagi | 1060 | |
| Electoral fraud in the United States | 1012 | The upcoming election turns this into a relevant topic. The article even notes the current Republican candidate both claimed this as for why he lost the popular vote in 2016 to Hillary Clinton, and for why he outright was defeated by Joe Biden four years later (he unsuccesfully sued, his party tried to change how the elections work, and his fans went too far in refusing defeat). |
| Brazil at the 2024 Summer Paralympics | 910 | A relatively recent emerging Olympic power that has won at least 10 medals in all editions since 1996, Brazil has also been a proven Paralympic potency since 1984, ranking 16th in the all-time Paralympic Games medal table (albeit one of the teams above them is the now defunct state of West Germany), probably a reflection of abrangent publicly funded health care. Paris 2024 had them rank fifth in the medal table with 89 medals, 25 of them golden. |
| List of Canadian hip hop musicians | 874 | Most people probably only know Drake, but one user is doing his best to extend this list. |
| 2024 US Open – Men's singles | 871 | In both genders, this year's tennis Grand Slams played on hard courts were won by the same player: after Aryna Sabalenka got the Australian Open-US Open double, it was time for Jannik Sinner to do the same, overcoming his adversary Taylor Fritz despite him having the support of the Flushing Meadows crowd. A notable fact is that aside from Sinner, the other three semifinalists - Fritz, Frances Tiafoe, and Jack Draper - were all reaching that phase of a Grand Slam for the first time. |
| 2024 Democratic National Convention | 809 | The 2024 DNC was held in Chicago from August 19 to 22, a loud, boisterous convention with lots and lots of speeches. It's also where delegates selected the presidential nominee. Kamala Harris, the current Vice-President who was literally the only candidate, was selected. |
| 2024 Summer Paralympics medal table | 757 | A few weeks after the Summer Olympics, it was time for athletes with disabilities to get the spotlight, in the same host city of Paris. Aside from the United States not being as dominating - they were third, behind China and Great Britain - a big difference for this year's Paralympics compared to the Olympics was the presence of nearly three times more Russians and Belarusians competing for no flag (they would have ranked fifth if not for the neutrality excluding them from the medal table, thus officially that place is from the aforementioned Brazil). |
| 2024 Ligas Departamentales del Perú | 745 | From para-athletes to regular ones, as one user made lots of updates on Peru's fifth division football tournament. |
| Black Myth: Wukong | 742 | A video game released on August 20 and based on the 16th century Chinese fantasy novel Journey to the West, a classic in Chinese literature. There was much hype surrounding its release (it topped Steam's best-selling chart and smashed the same platform's record for highest-concurrent player count, a record previously held by Elden Ring) and has released to positive reception. The game gained noteriety when its developer, Game Science, was accused of being sexist by IGN in November 2023, and the game got even more noteriety when streamers were instructed to not mention "feminist propaganda", "quarantine", "COVID-19", and Chinese politics, in order to comply with Chinese law. If the Chinese government doesn't appreciate things said about them, they can take you away like they did with Jack Ma. |
| This is a Wikipedia user page. This is not an encyclopedia article or the talk page for an encyclopedia article. If you find this page on any site other than Wikipedia, you are viewing a mirror site. Be aware that the page may be outdated and that the user whom this page is about may have no personal affiliation with any site other than Wikipedia. The original page is located at https://en.wikipedia.org/wiki/User:Alvaro. |